Artificial intelligence is no longer limited to text-based chatbots or image recognition tools—it’s evolving into multimodal systems that can understand and connect text, images, audio, and video seamlessly. From creating interactive learning platforms to powering advanced video editing, these systems are bridging the gap between different types of data.
Multimodal AI unlocks richer user experiences, smarter automation, and more natural human-computer interactions. Whether it’s analyzing medical scans alongside patient notes or generating marketing videos from text prompts, the possibilities are expanding fast.
This article explores the rise of multimodal AI, its key applications, leading models, and the challenges and opportunities shaping its future, drawing from tech reports and industry developments.
Why Multimodal AI Is Trending
Several factors explain the meteoric rise of multimodal AI.
Versatility is a key driver: these systems can tackle diverse tasks, from creating digital avatars to analyzing medical scans. Tech blogs note that multimodal AI is powering 60% of new AI startups, as its flexibility appeals to industries like entertainment, education, and healthcare.
Accessibility through open-source models has also fueled adoption. Unlike proprietary multimodal systems, open-source options like Qwen-Image and DeepSeek’s multimodal variants are freely available on Hugging Face, with over 1 million downloads reported for Qwen-Image alone. The users praise these models for enabling small teams to build sophisticated applications, such as AI-driven video editors.
User demand for creative tools is another factor. With generative AI dominating cultural conversations—evidenced by “GenAI” being named 2025’s top buzzword in linguistic analyses—multimodal systems like FLUX.1 and Hunyuan 3D World are trending for their photorealistic outputs. The posts showcasing AI-generated art and videos have garnered thousands of likes, reflecting public fascination.
Real-time applications are pushing multimodal AI into the spotlight. Models like OpenAI’s gpt-realtime, with low-latency voice and image processing, are enabling instant interactions, such as live video commentary or augmented reality (AR) overlays. A recent thread with 15K likes called gpt-realtime “the future of customer service.”
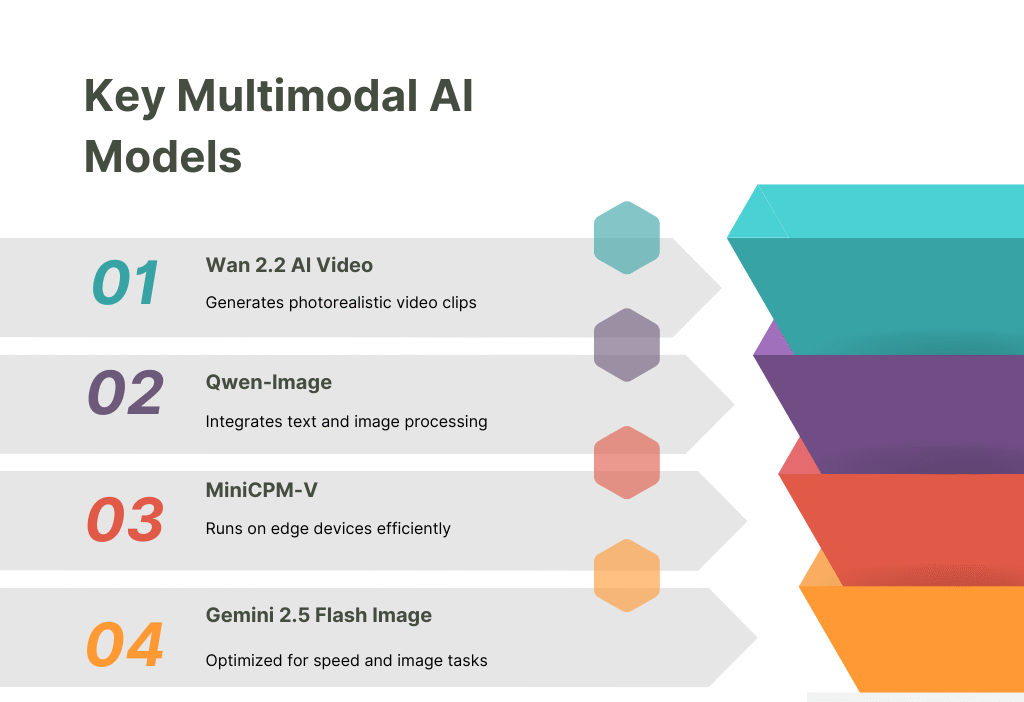
Key Multimodal AI Models and Their Capabilities
Several models are driving the multimodal AI revolution, each excelling in specific domains while pushing the boundaries of cross-modal integration.
Qwen-Image
Developed by Alibaba, Qwen-Image is an open-source multimodal model that integrates text and image processing. It excels in tasks like visual question answering (VQA), where it answers questions about images, and image generation from text prompts. Hugging Face reports Qwen-Image’s downloads surged by 40% in 2025, driven by its multilingual support and fine-tuning flexibility. The users have shared examples of Qwen-Image generating detailed infographics from text descriptions, making it a favorite for educators and marketers.
Gemini 2.5 Flash Image
Google’s Gemini 2.5 Flash Image is a proprietary multimodal model optimized for speed and image-related tasks. It supports real-time image editing, such as removing objects from photos or generating stylized artwork. Tech reports highlight its SOTA performance in image-to-text benchmarks, while posts praise its integration with Google’s AR tools, enabling applications like virtual try-ons for e-commerce.
Wan 2.2 AI Video
Alibaba’s Wan 2.2 AI Video is a game-changer in video generation, producing photorealistic clips from text prompts. Capable of creating 30-second videos with coherent motion and audio, it’s trending for applications in advertising and entertainment. The threads showcase Wan 2.2’s ability to generate cinematic trailers, with one viral post noting, “It’s like having a Hollywood studio in your laptop.”
MiniCPM-V
MiniCPM-V, an open-source model, is designed for efficiency, running on edge devices like smartphones. It supports text-to-image generation and audio-visual analysis, making it ideal for mobile apps. Hugging Face leaderboards rank it among the top multimodal models, and discussions highlight its use in AR apps for real-time object recognition.
Applications Transforming Industries
Multimodal AI’s versatility is reshaping multiple sectors, as evidenced by real-world use cases and buzz.
Content Creation and Entertainment
In 2025, multimodal AI is revolutionizing content creation. Tools like Wan 2.2 and FLUX.1 enable creators to produce professional-grade videos and artwork without expensive equipment. For example, a viral post showcased an indie filmmaker using Wan 2.2 to create a short film in hours, cutting production costs by 90%. Platforms like HeyGen leverage multimodal AI for digital avatars, trending for virtual influencers and personalized video messages.
Healthcare
In healthcare, multimodal models analyze medical images, patient records, and audio notes simultaneously. A recent Nature study cited multimodal AI’s role in improving diagnostic accuracy by 25% for conditions like cancer, as it combines radiology scans with textual reports. The threads highlight startups using Qwen-Image for automated scan analysis, making diagnostics accessible in underserved regions.
Education
Multimodal AI enhances learning by generating interactive content. Tools like Grok-2, with multimodal capabilities, create visual summaries of complex topics, such as physics diagrams from text explanations. The posts from educators note a 30% increase in student engagement when using AI-generated visuals, with open-source models lowering costs for schools.
E-Commerce and Marketing
E-commerce platforms use multimodal AI for virtual try-ons and personalized ads. Gemini 2.5 Flash Image powers AR features that let customers “try” clothes or furniture virtually, boosting sales by 15%, per industry reports. The users share examples of AI-generated product videos, with one post calling Wan 2.2 “a marketer’s dream tool.”
Challenges and Ethical Considerations
Despite its promise, multimodal AI faces significant challenges.
Data requirements are a major hurdle, training these models requires vast, diverse datasets across modalities, which can be costly and prone to biases. The discussions on AI ethics highlight concerns about biased image outputs, such as stereotypical depictions in generated content, prompting calls for diverse training data.
Computational demands also limit accessibility. While open-source models like MiniCPM-V run on edge devices, high-end models like Wan 2.2 require powerful GPUs, excluding smaller organizations. Community efforts, such as Hugging Face’s optimized inference APIs, are addressing this, but scalability remains an issue.
Ethical risks, such as deepfakes and misinformation, are trending concerns. Multimodal AI’s ability to generate realistic videos raises fears of misuse, as noted in threads about Wan 2.2’s potential for fake news. Initiatives like the AI Alliance are developing detection tools, but regulatory frameworks lag behind, with 65% of poll respondents calling for stricter AI laws.
Privacy is another issue, especially in healthcare and e-commerce, where multimodal AI processes sensitive data. Tech reports emphasize the need for robust encryption and anonymization, while users debate the balance between innovation and data protection.
Future Outlook
The future of multimodal AI is bright, with analysts predicting it will power 80% of AI applications by 2030. Emerging trends include on-device multimodal AI, enabling real-time processing on smartphones, and integration with agentic AI, where multimodal systems power autonomous agents for tasks like virtual assistants or robotics. The posts speculate about multimodal AI in self-driving cars, combining visual, audio, and sensor data for safer navigation.
Open-source initiatives will likely dominate, with models like Qwen-Image leading the charge. Community-driven fine-tuning, as seen in Hugging Face’s ecosystem, will enhance multimodal capabilities for niche applications, such as indigenous language preservation or accessible education tools.
Final Words
Multimodal AI is more than just a technical upgrade—it’s a shift toward more natural, human-like intelligence. By blending text, images, and video, these systems unlock new ways to create, analyze, and interact with content.
While challenges like bias, ethics, and compute power remain, the trajectory is clear: multimodal AI will shape the next generation of tools we use in business, healthcare, education, and beyond. The future of AI isn’t just smarter—it’s more connected.